- java.lang.Object
-
- java.lang.String
-
- All Implemented Interfaces:
- Serializable , CharSequence , Comparable < String >
public final class String extends Object implements Serializable, Comparable<String>, CharSequence
String类代表字符串。 Java程序中的所有字符串文字(例如"abc")都被实现为此类的实例。字符串不变; 它们的值在创建后不能被更改。 字符串缓冲区支持可变字符串。 因为String对象是不可变的,它们可以被共享。 例如:
String str = "abc";相当于:
char data[] = {'a', 'b', 'c'}; String str = new String(data);以下是一些如何使用字符串的示例:
System.out.println("abc"); String cde = "cde"; System.out.println("abc" + cde); String c = "abc".substring(2,3); String d = cde.substring(1, 2);String类包括用于检查序列的各个字符的方法,用于比较字符串,搜索字符串,提取子字符串以及创建将所有字符翻译为大写或小写的字符串的副本。 案例映射基于Character类指定的Unicode标准版本。Java语言为字符串连接运算符(+)提供特殊支持,并为其他对象转换为字符串。 字符串连接是通过
StringBuilder(或StringBuffer)类及其append方法实现的。 字符串转换是通过方法来实现toString,由下式定义Object和继承由在Java中的所有类。 有关字符串连接和转换的其他信息,请参阅Gosling,Joy和Steele, Java语言规范 。除非另有说明,否则传递null参数到此类中的构造函数或方法将导致抛出
NullPointerException。A
String表示UTF-16格式的字符串,其中补充字符由代理对表示 (有关详细信息,请参阅Character课程中的Character部分)。 索引值是指char代码单元,所以补充字符在String中使用两个String。String类提供处理Unicode代码点(即字符)的方法,以及用于处理Unicode代码单元(即char值)的方法。- 从以下版本开始:
- JDK1.0
- 另请参见:
-
Object.toString(),StringBuffer,StringBuilder,Charset, Serialized Form
-
-
Field Summary
Fields Modifier and Type Field and Description static Comparator<String>CASE_INSENSITIVE_ORDER一个比较器,按compareToIgnoreCase订购String对象。
-
构造方法摘要
构造方法 Constructor and Description String()初始化新创建的String对象,使其表示空字符序列。String(byte[] bytes)通过使用平台的默认字符集解码指定的字节数组来构造新的String。String(byte[] bytes, Charset charset)构造一个新的String由指定用指定的字节的数组解码charset 。String(byte[] ascii, int hibyte)已弃用此方法无法将字节正确转换为字符。 从JDK 1.1开始,首选的方法是通过String构造函数获取Charset,字符集名称,或者使用平台的默认字符集。String(byte[] bytes, int offset, int length)通过使用平台的默认字符集解码指定的字节子阵列来构造新的String。String(byte[] bytes, int offset, int length, Charset charset)构造一个新的String通过使用指定的指定字节子阵列解码charset 。String(byte[] ascii, int hibyte, int offset, int count)已弃用此方法无法将字节正确转换为字符。 从JDK 1.1开始,首选的方式是通过String构造函数获取Charset,字符集名称,或使用平台的默认字符集。String(byte[] bytes, int offset, int length, String charsetName)构造一个新的String通过使用指定的字符集解码指定的字节子阵列。String(byte[] bytes, String charsetName)构造一个新的String由指定用指定的字节的数组解码charset 。String(char[] value)分配一个新的String,以便它表示当前包含在字符数组参数中的字符序列。String(char[] value, int offset, int count)分配一个新的String,其中包含字符数组参数的子阵列中的字符。String(int[] codePoints, int offset, int count)String(String original)初始化新创建的String对象,使其表示与参数相同的字符序列; 换句话说,新创建的字符串是参数字符串的副本。String(StringBuffer buffer)分配一个新的字符串,其中包含当前包含在字符串缓冲区参数中的字符序列。String(StringBuilder builder)分配一个新的字符串,其中包含当前包含在字符串构建器参数中的字符序列。
-
方法摘要
所有方法 静态方法 接口方法 具体的方法 弃用的方法 Modifier and Type Method and Description charcharAt(int index)返回char指定索引处的值。intcodePointAt(int index)返回指定索引处的字符(Unicode代码点)。intcodePointBefore(int index)返回指定索引之前的字符(Unicode代码点)。intcodePointCount(int beginIndex, int endIndex)返回此String指定文本范围内的Unicode代码点数。intcompareTo(String anotherString)按字典顺序比较两个字符串。intcompareToIgnoreCase(String str)按字典顺序比较两个字符串,忽略病例差异。Stringconcat(String str)将指定的字符串连接到该字符串的末尾。booleancontains(CharSequence s)当且仅当此字符串包含指定的char值序列时才返回true。booleancontentEquals(CharSequence cs)将此字符串与指定的CharSequence进行CharSequence。booleancontentEquals(StringBuffer sb)将此字符串与指定的StringBuffer进行StringBuffer。static StringcopyValueOf(char[] data)相当于valueOf(char[])。static StringcopyValueOf(char[] data, int offset, int count)booleanendsWith(String suffix)测试此字符串是否以指定的后缀结尾。booleanequals(Object anObject)将此字符串与指定对象进行比较。booleanequalsIgnoreCase(String anotherString)将此String与其他String比较,忽略案例注意事项。static Stringformat(Locale l, String format, Object... args)使用指定的区域设置,格式字符串和参数返回格式化的字符串。static Stringformat(String format, Object... args)使用指定的格式字符串和参数返回格式化的字符串。byte[]getBytes()使用平台的默认字符集将此String编码为字节序列,将结果存储到新的字节数组中。byte[]getBytes(Charset charset)使用给定的charset将该String编码为字节序列,将结果存储到新的字节数组中。voidgetBytes(int srcBegin, int srcEnd, byte[] dst, int dstBegin)已弃用此方法无法将字符正确转换为字节。 从JDK 1.1开始,首选的方法是通过getBytes()方法,该方法使用平台的默认字符集。byte[]getBytes(String charsetName)使用命名的字符集将此String编码为字节序列,将结果存储到新的字节数组中。voidgetChars(int srcBegin, int srcEnd, char[] dst, int dstBegin)将此字符串中的字符复制到目标字符数组中。inthashCode()返回此字符串的哈希码。intindexOf(int ch)返回指定字符第一次出现的字符串内的索引。intindexOf(int ch, int fromIndex)返回指定字符第一次出现的字符串内的索引,以指定的索引开始搜索。intindexOf(String str)返回指定子字符串第一次出现的字符串内的索引。intindexOf(String str, int fromIndex)返回指定子串的第一次出现的字符串中的索引,从指定的索引开始。Stringintern()返回字符串对象的规范表示。booleanisEmpty()static Stringjoin(CharSequence delimiter, CharSequence... elements)返回一个新的字符串,由CharSequence elements的副本组成,并附有指定的delimiter的delimiter。static Stringjoin(CharSequence delimiter, Iterable<? extends CharSequence> elements)返回一个新String的副本组成CharSequence elements与指定的副本一起加入delimiter。intlastIndexOf(int ch)返回指定字符的最后一次出现的字符串中的索引。intlastIndexOf(int ch, int fromIndex)返回指定字符的最后一次出现的字符串中的索引,从指定的索引开始向后搜索。intlastIndexOf(String str)返回指定子字符串最后一次出现的字符串中的索引。intlastIndexOf(String str, int fromIndex)返回指定子字符串的最后一次出现的字符串中的索引,从指定索引开始向后搜索。intlength()返回此字符串的长度。booleanmatches(String regex)告诉这个字符串是否匹配给定的 regular expression 。intoffsetByCodePoints(int index, int codePointOffset)返回此String内的指数,与indexcodePointOffset代码点。booleanregionMatches(boolean ignoreCase, int toffset, String other, int ooffset, int len)测试两个字符串区域是否相等。booleanregionMatches(int toffset, String other, int ooffset, int len)测试两个字符串区域是否相等。Stringreplace(char oldChar, char newChar)返回从替换所有出现的导致一个字符串oldChar在此字符串newChar。Stringreplace(CharSequence target, CharSequence replacement)将与字面目标序列匹配的字符串的每个子字符串替换为指定的字面替换序列。StringreplaceAll(String regex, String replacement)用给定的替换替换与给定的 regular expression匹配的此字符串的每个子字符串。StringreplaceFirst(String regex, String replacement)用给定的替换替换与给定的 regular expression匹配的此字符串的第一个子字符串。String[]split(String regex)将此字符串分割为给定的 regular expression的匹配。String[]split(String regex, int limit)将这个字符串拆分为给定的 regular expression的匹配。booleanstartsWith(String prefix)测试此字符串是否以指定的前缀开头。booleanstartsWith(String prefix, int toffset)测试在指定索引处开始的此字符串的子字符串是否以指定的前缀开头。CharSequencesubSequence(int beginIndex, int endIndex)返回一个字符序列,该序列是该序列的子序列。Stringsubstring(int beginIndex)返回一个字符串,该字符串是此字符串的子字符串。Stringsubstring(int beginIndex, int endIndex)返回一个字符串,该字符串是此字符串的子字符串。char[]toCharArray()将此字符串转换为新的字符数组。StringtoLowerCase()将所有在此字符String使用默认语言环境的规则,以小写。StringtoLowerCase(Locale locale)将所有在此字符String,以降低使用给定的规则情况下Locale。StringtoString()此对象(已经是字符串!)本身已被返回。StringtoUpperCase()将所有在此字符String使用默认语言环境的规则大写。StringtoUpperCase(Locale locale)将所有在此字符String使用给定的规则,大写Locale。Stringtrim()返回一个字符串,其值为此字符串,并删除任何前导和尾随空格。static StringvalueOf(boolean b)返回boolean参数的字符串boolean形式。static StringvalueOf(char c)返回char参数的字符串char形式。static StringvalueOf(char[] data)返回char数组参数的字符串char形式。static StringvalueOf(char[] data, int offset, int count)返回char数组参数的特定子阵列的字符串char形式。static StringvalueOf(double d)返回double参数的字符串double形式。static StringvalueOf(float f)返回float参数的字符串float形式。static StringvalueOf(int i)返回int参数的字符串int形式。static StringvalueOf(long l)返回long参数的字符串long形式。static StringvalueOf(Object obj)返回Object参数的字符串Object形式。-
Methods inherited from class java.lang.Object
clone, finalize, getClass, notify, notifyAll, wait, wait, wait
-
Methods inherited from interface java.lang.CharSequence
chars, codePoints
-
-
-
-
字段详细信息
-
CASE_INSENSITIVE_ORDER
public static final Comparator<String> CASE_INSENSITIVE_ORDER
一个比较器,按compareToIgnoreCase命令String对象。 该比较器可串行化。请注意,此比较器不会考虑区域设置,并将导致对某些区域设置的排序不满意。 java.text包提供了Collators来允许区域设置敏感的排序。
- 从以下版本开始:
- 1.2
- 另请参见:
-
Collator.compare(String, String)
-
-
构造方法详细信息
-
String
public String()
初始化新创建的String对象,以使其表示空字符序列。 请注意,使用此构造函数是不必要的,因为Strings是不可变的。
-
String
public String(String original)
初始化新创建的String对象,使其表示与参数相同的字符序列; 换句话说,新创建的字符串是参数字符串的副本。 除非需要original的显式副本,original使用此构造函数是不必要的,因为Strings是不可变的。- 参数
-
original- AString
-
String
public String(char[] value)
分配一个新的String,以便它表示当前包含在字符数组参数中的字符序列。 字符数组的内容被复制; 字符数组的后续修改不会影响新创建的字符串。- 参数
-
value- 字符串的初始值
-
String
public String(char[] value, int offset, int count)分配一个新的String,其中包含字符数组参数的子阵列中的字符。offset参数是子阵列的第一个字符的索引,count参数指定子阵列的长度。 副本的内容被复制; 字符数组的后续修改不会影响新创建的字符串。- 参数
-
value- 作为字符源的数组 -
offset- 初始偏移量 -
count- 长度 - 异常
-
IndexOutOfBoundsException- 如果offset和count参数的索引字符超出了value数组的界限
-
String
public String(int[] codePoints, int offset, int count)分配一个新的String,其中包含Unicode code point数组参数的子阵列中的字符 。offset参数是子阵列的第一个代码点的索引,count参数指定子阵列的长度。 子阵列的内容转换为chars; int数组的int不影响新创建的字符串。- 参数
-
codePoints- 作为Unicode代码点的源的数组 -
offset- 初始偏移量 -
count- 长度 - 异常
-
IllegalArgumentException- 如果在codePoints中找到任何无效的Unicode代码点 -
IndexOutOfBoundsException- 如果offset和count参数的索引字符在codePoints数组的边界之外 - 从以下版本开始:
- 1.5
-
String
@Deprecated public String(byte[] ascii, int hibyte, int offset, int count)
从一个8位整数值数组的子阵列中分配一个新的String。offset参数是子阵列的第一个字节的索引,count参数指定子阵列的长度。子阵列中的每个
bytechar为char,如上述方法中所述。- 参数
-
ascii- 要转换为字符的字节 -
hibyte- 每个16位Unicode代码单元的前8位 -
offset- 初始偏移量 -
count- 长度 - 异常
-
IndexOutOfBoundsException- 如果offset或count参数无效 - 另请参见:
-
String(byte[], int),String(byte[], int, int, java.lang.String),String(byte[], int, int, java.nio.charset.Charset),String(byte[], int, int),String(byte[], java.lang.String),String(byte[], java.nio.charset.Charset),String(byte[])
-
String
@Deprecated public String(byte[] ascii, int hibyte)
分配一个新的String,其中包含由8位整数值数组构成的字符。 结果字符串中的每个字符c由字节数组中的相应组件b构成,使得:c == (char)(((hibyte & 0xff) << 8) | (b & 0xff))- 参数
-
ascii- 要转换为字符的字节 -
hibyte- 每个16位Unicode代码单元的前8位 - 另请参见:
-
String(byte[], int, int, java.lang.String),String(byte[], int, int, java.nio.charset.Charset),String(byte[], int, int),String(byte[], java.lang.String),String(byte[], java.nio.charset.Charset),String(byte[])
-
String
public String(byte[] bytes, int offset, int length, String charsetName) throws UnsupportedEncodingException构造一个新的String通过使用指定的字符集解码指定的字节子阵列。 新的String的长度是字符集的函数,因此可能不等于子阵列的长度。给定字节在给定字符集中无效时,此构造函数的行为是未指定的。 当需要更多的解码过程控制时,应使用
CharsetDecoder类。- 参数
-
bytes- 要解码为字符的字节 -
offset- 要解码的第一个字节的索引 -
length- 要解码的字节数 -
charsetName- 支持的名称charset - 异常
-
UnsupportedEncodingException- 如果不支持命名的字符集 -
IndexOutOfBoundsException- 如果offset和length参数的索引字符在bytes数组的边界之外 - 从以下版本开始:
- JDK1.1
-
String
public String(byte[] bytes, int offset, int length, Charset charset)构造一个新的String通过使用指定的指定字节子阵列解码charset 。 新的String的长度是字符集的函数,因此可能不等于子数组的长度。此方法总是用此字符集的默认替换字符串替换格式错误的输入和不可映射字符序列。 当需要更多的解码过程控制时,应使用
CharsetDecoder类。- 参数
-
bytes- 要解码为字符的字节 -
offset- 要解码的第一个字节的索引 -
length- 要解码的字节数 -
charset-该charset要使用的解码bytes - 异常
-
IndexOutOfBoundsException- 如果offset和length参数在bytes数组的范围之外的索引字符 - 从以下版本开始:
- 1.6
-
String
public String(byte[] bytes, String charsetName) throws UnsupportedEncodingException构造一个新的String由指定用指定的字节的数组解码charset 。 新的String的长度是字符集的函数,因此可能不等于字节数组的长度。给定字节在给定字符集中无效时,此构造函数的行为是未指定的。 当需要更多的解码过程控制时,应使用
CharsetDecoder类。- 参数
-
bytes- 要解码为字符的字节 -
charsetName- 支持的名称charset - 异常
-
UnsupportedEncodingException- 如果不支持命名的字符集 - 从以下版本开始:
- JDK1.1
-
String
public String(byte[] bytes, Charset charset)构造一个新的String由指定用指定的字节的数组解码charset 。 新的String的长度是字符集的函数,因此可能不等于字节数组的长度。此方法总是用此字符集的默认替换字符串替换格式错误的输入和不可映射字符序列。 当需要更多的解码过程控制时,应使用
CharsetDecoder类。- 参数
-
bytes- 要解码为字符的字节 -
charset-该charset要使用的解码bytes - 从以下版本开始:
- 1.6
-
String
public String(byte[] bytes, int offset, int length)通过使用平台的默认字符集解码指定的字节子阵列来构造新的String。 新的String的长度是字符集的函数,因此可能不等于子数组的长度。指定字节在默认字符集中无效时,此构造函数的行为是未指定的。 当需要更多的解码过程控制时,应使用
CharsetDecoder类。- 参数
-
bytes- 要解码为字符的字节 -
offset- 要解码的第一个字节的索引 -
length- 要解码的字节数 - 异常
-
IndexOutOfBoundsException- 如果offset和length参数的索引字符在bytes数组的边界之外 - 从以下版本开始:
- JDK1.1
-
String
public String(byte[] bytes)
通过使用平台的默认字符集解码指定的字节数组来构造新的String。 新的String的长度是字符集的函数,因此可能不等于字节数组的长度。指定字节在默认字符集中无效时,此构造函数的行为是未指定的。 当需要对解码过程进行更多的控制时,应使用
CharsetDecoder类。- 参数
-
bytes- 要解码为字符的字节 - 从以下版本开始:
- JDK1.1
-
String
public String(StringBuffer buffer)
分配一个新的字符串,其中包含当前包含在字符串缓冲区参数中的字符序列。 字符串缓冲区的内容被复制; 字符串缓冲区的后续修改不会影响新创建的字符串。- 参数
-
buffer- AStringBuffer
-
String
public String(StringBuilder builder)
分配一个新的字符串,其中包含当前包含在字符串构建器参数中的字符序列。 字符串构建器的内容被复制; 字符串构建器的后续修改不会影响新创建的字符串。提供此构造函数以便迁移到
StringBuilder。 通过toString方法从字符串构建器获取字符串可能运行速度更快,通常是首选。- 参数
-
builder- AStringBuilder - 从以下版本开始:
- 1.5
-
-
方法详细信息
-
length
public int length()
返回此字符串的长度。 长度等于字符串中的数字Unicode code units 。- Specified by:
-
length在界面CharSequence - 结果
- 由该对象表示的字符序列的长度。
-
isEmpty
public boolean isEmpty()
- 结果
-
true如果length()是0,否则false - 从以下版本开始:
- 1.6
-
charAt
public char charAt(int index)
返回char指定索引处的值。 指数范围为0至length() - 1。 该序列的第一个char值在索引0,下一个索引为1,依此类推,与数组索引一样。如果
char由索引指定的值是surrogate ,则返回所述替代值。- Specified by:
-
charAt在界面CharSequence - 参数
-
index-char值的指数。 - 结果
-
所述
char此字符串的指定索引处的值。 第一个char值是索引0。 - 异常
-
IndexOutOfBoundsException- 如果index参数为负数或不小于此字符串的长度。
-
codePointAt
public int codePointAt(int index)
返回指定索引处的字符(Unicode代码点)。 该索引指的是char值(Unicode码单位),范围从0到length()- 1。如果在给定索引处指定的
char值处于高代理范围内,则以下指数小char值String的长度,并且下列指数的char值处于低代理范围,则补码代码相应的这个代理对被退回。 否则,返回给定索引处的char值。- 参数
-
index- 指数为char值 - 结果
-
字符的代码点值在
index - 异常
-
IndexOutOfBoundsException- 如果index参数为负数或不小于此字符串的长度。 - 从以下版本开始:
- 1.5
-
codePointBefore
public int codePointBefore(int index)
返回指定索引之前的字符(Unicode代码点)。 索引指的是char值(Unicode代码单位),范围从1到length。如果
char的(index - 1)为(index - 1),(index - 2)为char为(index - 2)为char为(index - 2),为高代数范围,则返回替代对的补码。 如果char在值index - 1是未配对的低代理或一个高代理,则返回所述替代值。- 参数
-
index- 应该返回的代码点之后的索引 - 结果
- Unicode代码点值在给定索引之前。
- 异常
-
IndexOutOfBoundsException- 如果index参数小于1或大于此字符串的长度。 - 从以下版本开始:
- 1.5
-
codePointCount
public int codePointCount(int beginIndex, int endIndex)返回此String指定文本范围内的Unicode代码点数。 文本范围始于指定beginIndex并延伸到char在索引endIndex - 1。 因此,文本范围的长度(在char秒)为endIndex-beginIndex。 文本范围内的非配对替代品,每一个代码点都是一样的。- 参数
-
beginIndex- 索引到第一个char的文本范围。 -
endIndex- 最后一个char之后的索引。 - 结果
- 指定文本范围内的Unicode代码点数
- 异常
-
IndexOutOfBoundsException- 如果beginIndex为负数,或endIndex大于该String的长度,或beginIndex大于endIndex。 - 从以下版本开始:
- 1.5
-
offsetByCodePoints
public int offsetByCodePoints(int index, int codePointOffset)返回此String内的指数,该指数与index(codePointOffset代码点相抵消。 由index和codePointOffset给出的文本范围内的非配对替代codePointOffset作为一个代码点。- 参数
-
index- 要偏移的索引 -
codePointOffset- 代码点的偏移量 - 结果
-
这个指数在这个
String - 异常
-
IndexOutOfBoundsException-如果index接着这个长度负或更大String,或如果codePointOffset为正,并且开始与该子串index有少于codePointOffset代码点,或者如果codePointOffset为负且前的子字符串index具有比的绝对值较少的codePointOffset代码点。 - 从以下版本开始:
- 1.5
-
getChars
public void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin)将此字符串中的字符复制到目标字符数组中。要复制的第一个字符是索引
srcBegin; 要复制的最后一个字符在索引srcEnd-1(因此要复制的srcEnd-srcBegin总数为srcEnd-srcBegin)。 字符被复制到的子阵列dst开始于索引dstBegin和在索引结束:dstbegin + (srcEnd-srcBegin) - 1- 参数
-
srcBegin- 要复制的字符串中第一个字符的索引。 -
srcEnd- 要复制的字符串中最后一个字符后面的索引。 -
dst- 目标数组。 -
dstBegin- 目标数组中的起始偏移量。 - 异常
-
IndexOutOfBoundsException- 如果满足以下条件:-
srcBegin为负数。 -
srcBegin大于srcEnd -
srcEnd大于此字符串的长度 -
dstBegin为负数 -
dstBegin+(srcEnd-srcBegin)大于dst.length
-
-
getBytes
@Deprecated public void getBytes(int srcBegin, int srcEnd, byte[] dst, int dstBegin)
将此字符串中的字符复制到目标字节数组中。 每个字节接收相应字符的8个低位。 每个字符的八个高位不被复制,也不以任何方式参与转移。要复制的第一个字符是索引
srcBegin; 要复制的最后一个字符在索引srcEnd-1。 要复制的srcEnd-srcBegin总数为srcEnd-srcBegin。 转换为字节的字符被复制到dst的子阵列中,从索引dstBegin开始,以索引结尾:dstbegin + (srcEnd-srcBegin) - 1- 参数
-
srcBegin- 要复制的字符串中第一个字符的索引 -
srcEnd- 要复制的字符串中最后一个字符后的索引 -
dst- 目的数组 -
dstBegin- 目标数组中的起始偏移量 - 异常
-
IndexOutOfBoundsException- 如果满足以下条件:-
srcBegin为负数 -
srcBegin大于srcEnd -
srcEnd大于此String的长度 -
dstBegin为负数 -
dstBegin+(srcEnd-srcBegin)大于dst.length
-
-
getBytes
public byte[] getBytes(String charsetName) throws UnsupportedEncodingException
使用命名的字符集将此String编码为字节序列,将结果存储到新的字节数组中。此字符串不能在给定字符集中编码时,此方法的行为是未指定的。 当需要对编码过程进行更多控制时,应使用
CharsetEncoder类。- 参数
-
charsetName- 支持的名称charset - 结果
- 结果字节数组
- 异常
-
UnsupportedEncodingException- 如果不支持命名的字符集 - 从以下版本开始:
- JDK1.1
-
getBytes
public byte[] getBytes(Charset charset)
使用给定的charset将该String编码为一个字节序列,将结果存储到新的字节数组中。此方法总是用此字符集的默认替换字节数组替换格式错误的输入和不可映射字符序列。 当需要对编码过程的更多控制时,应使用
CharsetEncoder类。- 参数
-
charset-该Charset被用于编码String - 结果
- 结果字节数组
- 从以下版本开始:
- 1.6
-
getBytes
public byte[] getBytes()
使用平台的默认字符集将此String编码为字节序列,将结果存储到新的字节数组中。当该字符串不能在默认字符集中编码时,此方法的行为是未指定的。 当需要对编码过程进行更多控制时,应使用
CharsetEncoder类。- 结果
- 结果字节数组
- 从以下版本开始:
- JDK1.1
-
equals
public boolean equals(Object anObject)
将此字符串与指定对象进行比较。 其结果是true当且仅当该参数不是null并且是String对象,表示相同的字符序列作为该对象。- 重写:
-
equals在Object - 参数
-
anObject- 对比这个String的对象 - 结果
-
true如果给定的对象代表一个String等效于这个字符串,false否则 - 另请参见:
-
compareTo(String),equalsIgnoreCase(String)
-
contentEquals
public boolean contentEquals(StringBuffer sb)
将此字符串与指定的StringBuffer进行StringBuffer。 其结果是true如果并且如果该只String表示的字符作为指定的相同序列StringBuffer。 该方法在StringBuffer上StringBuffer。- 参数
-
sb-StringBuffer将此String对比 - 结果
-
true如果此String表示相同的字符序列作为指定StringBuffer,false否则 - 从以下版本开始:
- 1.4
-
contentEquals
public boolean contentEquals(CharSequence cs)
将此字符串与指定的CharSequence进行CharSequence。 其结果是true如果并且如果该只String表示char值的相同序列与指定序列。 请注意,如果CharSequence是StringBuffer那么该方法将同步它。- 参数
-
cs- 比较这个String的序列 - 结果
-
true如果这个String表示与指定序列相同的char值序列,false否则 - 从以下版本开始:
- 1.5
-
equalsIgnoreCase
public boolean equalsIgnoreCase(String anotherString)
将此String与其他String比较,忽略案例注意事项。 如果两个字符串的长度相同,并且两个字符串中的相应字符等于忽略大小写,则两个字符串被认为是相等的。如果以下至少一个为真,则两个字符
c1和c2被认为是相同的忽略情况:- 两个字符相同(与
==操作符相比) - 将方法
Character.toUpperCase(char)应用于每个字符产生相同的结果 - 将方法
Character.toLowerCase(char)应用于每个字符产生相同的结果
- 参数
-
anotherString-String将此String对比 - 结果
-
true如果参数不是null,它代表等效的String忽略大小写;false否则 - 另请参见:
-
equals(Object)
- 两个字符相同(与
-
compareTo
public int compareTo(String anotherString)
按字典顺序比较两个字符串。 比较是基于字符串中每个字符的Unicode值。 由该String对象表示的字符序列按字典顺序与由参数字符串表示的字符序列进行比较。 如果String对象按字典顺序排列在参数字符串之前,结果为负整数。 结果是一个正整数,如果String对象按字典顺序跟随参数字符串。 如果字符串相等,结果为零;compareTo返回0,当equals(Object)方法将返回true。这是字典排序的定义。 如果两个字符串不同,则它们在某些索引处具有不同的字符,这两个字符串是两个字符串的有效索引,或者它们的长度不同,或两者都是不同的。 如果它们在一个或多个索引位置具有不同的字符,则令k为最小的索引; 那么在位置k处的字符具有较小值的字符串,如通过使用<运算符确定的,以字典顺序位于另一个字符串之前。 在这种情况下,
compareTo返回两个字符串中位置k处的两个字符值的差值,即值:
如果没有它们不同的索引位置,则较短的字符串按字典顺序位于较长的字符串之前。 在这种情况下,this.charAt(k)-anotherString.charAt(k)
compareTo返回字符串长度的差异 - 即值:this.length()-anotherString.length()
- Specified by:
-
compareTo在界面Comparable<String> - 参数
-
anotherString- 要比较的String。 - 结果
-
如果参数字符串等于此字符串,则值为
0; 一个值小于0如果这个字符串的字典比字符串参数小; 如果此字符串的字典大小超过字符串参数,则值大于0。
-
compareToIgnoreCase
public int compareToIgnoreCase(String str)
按字典顺序比较两个字符串,忽略病例差异。 此方法返回一个整数,其标志是调用的compareTo与在不同的情况下已经被淘汰,通过调用字符串的规范化版本Character.toLowerCase(Character.toUpperCase(character))上的每一个字符。请注意,此方法不场所考虑,并会导致特定的语言环境不满意的排序。 java.text包提供了整理器来允许区域设置敏感的排序。
- 参数
-
str- 要比较的String。 - 结果
- 指定的String大于等于或小于此String的负整数,零或正整数,忽略大小写注意事项。
- 从以下版本开始:
- 1.2
- 另请参见:
-
Collator.compare(String, String)
-
regionMatches
public boolean regionMatches(int toffset, String other, int ooffset, int len)测试两个字符串区域是否相等。这个
String对象的子字符串与其他参数的子字符串进行比较。 如果这些子串表示相同的字符序列,结果是真的。 要比较的String对象的子String从索引toffset开始,长度为len。 其他要比较的ooffset始于索引ooffset,长度为len。 结果是false当且仅当以下至少有一个是真的:-
toffset为负数。 -
ooffset是否定的。 -
toffset+len大于此String对象的长度。 -
ooffset+len大于另一个参数的长度。 - 有一些非负整数k小于
len,使得:this.charAt(toffset +k) != other.charAt(ooffset +k)
- 参数
-
toffset- 该字符串toffset的起始偏移量。 -
other- 字符串参数。 -
ooffset- 字符串参数ooffset的起始偏移量。 -
len- 要比较的字符数。 - 结果
-
true如果此字符串的指定子区域与字符串参数的指定子区域完全匹配;false否则。
-
-
regionMatches
public boolean regionMatches(boolean ignoreCase, int toffset, String other, int ooffset, int len)测试两个字符串区域是否相等。此
String对象的子字符串与参数other。 如果这些子字符串表示相同的字符序列,则结果为true,如果且仅当ignoreCase为真,忽略大小写。 此String对象的子String将从索引toffset开始,长度为len。 要比较的other的other始于索引ooffset,长度为len。 结果是false当且仅当至少有以下一个是真的:-
toffset为负数。 -
ooffset为负数。 -
toffset+len大于此String对象的长度。 -
ooffset+len大于另一个参数的长度。 -
ignoreCase是false,并且有一些非负整数k小于len,使得:this.charAt(toffset+k) != other.charAt(ooffset+k)
-
ignoreCase是true,有一些非负整数k小于len,使得:
和:Character.toLowerCase(this.charAt(toffset+k)) != Character.toLowerCase(other.charAt(ooffset+k))Character.toUpperCase(this.charAt(toffset+k)) != Character.toUpperCase(other.charAt(ooffset+k))
- 参数
-
ignoreCase- 如果true,true时忽略大小写。 -
toffset- 该字符串toffset的起始偏移量。 -
other- 字符串参数。 -
ooffset- 字符串参数ooffset的起始偏移量。 -
len- 要比较的字符数。 - 结果
-
true如果此字符串的指定子区域匹配字符串参数的指定子区域;false否则。 匹配是否精确或不区分大小写取决于ignoreCase参数。
-
-
startsWith
public boolean startsWith(String prefix, int toffset)
测试在指定索引处开始的此字符串的子字符串是否以指定的前缀开头。- 参数
-
prefix- 前缀。 -
toffset- 在哪里开始查找这个字符串。 - 结果
-
true如果由参数表示的字符序列是从索引toffset开始的此对象的子字符串的前缀;false否则。 如果toffset为负数或大于此String对象的长度,则结果为false; 否则结果与表达式的结果相同this.substring(toffset).startsWith(prefix)
-
startsWith
public boolean startsWith(String prefix)
测试此字符串是否以指定的前缀开头。- 参数
-
prefix- 前缀。 - 结果
-
true如果由参数表示的字符序列是由该字符串表示的字符序列的前缀;false否则。 还需要注意的是true如果参数为空字符串或等于该将被返回String如由所确定的对象equals(Object)方法。 - 从以下版本开始:
- 1. 0
-
endsWith
public boolean endsWith(String suffix)
测试此字符串是否以指定的后缀结尾。- 参数
-
suffix- 后缀。 - 结果
-
true如果由参数表示的字符序列是由该对象表示的字符序列的后缀;false否则。 注意,结果将是true如果参数是空字符串或等于该String如由所确定的对象equals(Object)方法。
-
hashCode
public int hashCode()
返回此字符串的哈希码。String对象的哈希代码计算为
使用s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
int算术,其中s[i]是字符串的第i个字符,n是字符串的长度,^表示取幂。 (空字符串的哈希值为零)- 重写:
-
hashCode在类别Object - 结果
- 该对象的哈希码值。
- 另请参见:
-
Object.equals(java.lang.Object),System.identityHashCode(java.lang.Object)
-
indexOf
public int indexOf(int ch)
返回指定字符第一次出现的字符串内的索引。 如果与值的字符ch在此表示的字符序列发生String第一事件发生之对象,则索引(在Unicode代码单元)被返回。 对于从0到0xFFFF(含)范围内的ch的值,这是最小值k ,使得:
是真的。 对于this.charAt(k) == ch
ch其他值,它是最小值k ,使得:
是真的。 在这两种情况下,如果此字符串中没有此类字符,则返回this.codePointAt(k) == ch
-1。- 参数
-
ch- 一个字符(Unicode代码点)。 - 结果
-
在通过该对象表示的字符序列的字符的第一次出现的索引,或
-1如果字符不会发生。
-
indexOf
public int indexOf(int ch, int fromIndex)返回指定字符第一次出现的字符串内的索引,以指定的索引开始搜索。如果与值的字符
ch在此表示的字符序列发生String的索引不小于在对象fromIndex,则返回第一个这样的匹配项的索引。 对于从0到0xFFFF(含)范围内的ch的值,这是最小值k ,使得:
是真的。 对于(this.charAt(k) == ch)
&&(k >= fromIndex)ch其他值,它是最小值k ,使得:
是真的。 在这两种情况下,如果这个字符串在位置(this.codePointAt(k) == ch)
&&(k >= fromIndex)fromIndex之间或之后没有出现,则返回-1。fromIndex的价值没有
fromIndex。 如果它是否定的,它具有与零一样的效果:可以搜索整个字符串。 如果它大于此字符串的长度,它具有与该字符串的长度相等的效果:-1被返回。所有索引在
char值(Unicode代码单位)中char。- 参数
-
ch- 一个字符(Unicode代码点)。 -
fromIndex- 开始搜索的索引。 - 结果
-
在通过该对象,它是大于或等于表示的字符序列的字符的第一次出现的索引
fromIndex,或-1如果不发生的字符。
-
lastIndexOf
public int lastIndexOf(int ch)
返回指定字符的最后一次出现的字符串中的索引。 对于从0到0xFFFF(含)范围内的ch的值,ch的索引(以Unicode代码为单位)是最大的值k ,使得:
是真的。 对于this.charAt(k) == ch
ch其他值,它是最大值k ,使得:
是真的。 在任何一种情况下,如果此字符串中没有此类字符,则返回this.codePointAt(k) == ch
-1。 String从最后一个字符开始String搜索。- 参数
-
ch- 一个字符(Unicode代码点)。 - 结果
-
在通过该对象表示的字符序列的字符的最后一次出现的索引,或
-1如果字符不会发生。
-
lastIndexOf
public int lastIndexOf(int ch, int fromIndex)返回指定字符的最后一次出现的字符串中的索引,从指定的索引开始向后搜索。 对于从0到0xFFFF(含)范围内的ch的值,返回的索引是最大值k ,使得:
是真的。 对于(this.charAt(k) == ch)
&&(k <= fromIndex)ch其他值,它是最大的值k ,使得:
是真的。 在这两种情况下,如果此字符串在位置(this.codePointAt(k) == ch)
&&(k <= fromIndex)fromIndex之前或之后没有出现这样的字符,则返回-1。所有索引在
char值(Unicode代码单位)中char。- 参数
-
ch- 一个字符(Unicode代码点)。 -
fromIndex- 开始搜索的索引。 对fromIndex的价值没有fromIndex。 如果它大于或等于该字符串的长度,它具有与等于该字符串长度小于1的效果相同的效果:可以搜索整个字符串。 如果它是负的,它具有与-1:-1相同的效果。 - 结果
-
在通过该对象,它是小于或等于表示的字符序列的字符的最后一次出现的索引
fromIndex,或-1如果该字符不该点之前发生。
-
indexOf
public int indexOf(String str)
返回指定子字符串第一次出现的字符串内的索引。返回的索引是其中的最小值k :
如果k的值不存在,则返回this.startsWith(str, k)
-1。- 参数
-
str- 要搜索的子字符串。 - 结果
-
指定的子串,或第一次出现的索引
-1如果不存在这样的发生。
-
indexOf
public int indexOf(String str, int fromIndex)
返回指定子串的第一次出现的字符串中的索引,从指定的索引开始。返回的索引是其中的最小值k :
如果不存在这样的k值,则返回k >= fromIndex
&&this.startsWith(str, k)-1。- 参数
-
str- 要搜索的子字符串。 -
fromIndex- 从fromIndex开始搜索的索引。 - 结果
-
指定的字符串的第一个出现的索引,开始指定索引处,或
-1如果不存在这样的发生。
-
lastIndexOf
public int lastIndexOf(String str)
返回指定子字符串最后一次出现的字符串中的索引。 空字符串“”的最后一次出现被认为发生在索引值this.length()。返回的索引是其中的最大值k :
如果没有k的值存在,则返回this.startsWith(str, k)
-1。- 参数
-
str- 要搜索的子字符串。 - 结果
-
指定的子串,或最后一次出现的索引
-1如果不存在这样的发生。
-
lastIndexOf
public int lastIndexOf(String str, int fromIndex)
返回指定子字符串的最后一次出现的字符串中的索引,从指定索引开始向后搜索。返回的索引是其中的最大值k :
如果k的值不存在,则返回k
<=fromIndex&&this.startsWith(str, k)-1。- 参数
-
str- 要搜索的子字符串。 -
fromIndex- 开始搜索的索引。 - 结果
-
指定子字符串的最后一个匹配的索引,从指定的索引,或向后搜索
-1如果不存在这样的发生。
-
substring
public String substring(int beginIndex)
返回一个字符串,该字符串是此字符串的子字符串。 子字符串以指定索引处的字符开头,并扩展到该字符串的末尾。例子:
"unhappy".substring(2) returns "happy" "Harbison".substring(3) returns "bison" "emptiness".substring(9) returns "" (an empty string)
- 参数
-
beginIndex- 开始索引(含)。 - 结果
- 指定的子字符串。
- 异常
-
IndexOutOfBoundsException- 如果beginIndex为负或大于此String对象的长度。
-
substring
public String substring(int beginIndex, int endIndex)
返回一个字符串,该字符串是此字符串的子字符串。 子串开始于指定beginIndex并延伸到字符索引endIndex - 1。 因此,子串的长度为endIndex-beginIndex。例子:
"hamburger".substring(4, 8) returns "urge" "smiles".substring(1, 5) returns "mile"
- 参数
-
beginIndex- 开始索引,包括。 -
endIndex- 结束索引,独家。 - 结果
- 指定的子字符串。
- 异常
-
IndexOutOfBoundsException- 如果beginIndex为负数,或endIndex大于该String对象的长度,或beginIndex大于endIndex。
-
subSequence
public CharSequence subSequence(int beginIndex, int endIndex)
返回一个字符序列,该序列是该序列的子序列。调用此方法的形式
行为与调用完全相同str.subSequence(begin, end)
str.substring(begin, end)
- Specified by:
-
subSequence在界面CharSequence - API Note:
-
该方法定义为
String类可以实现CharSequence接口。 - 参数
-
beginIndex- 开始索引,包括。 -
endIndex- 结束索引,排他。 - 结果
- 指定的子序列。
- 异常
-
IndexOutOfBoundsException- 如果beginIndex或endIndex为负数,如果endIndex大于length(),或者如果beginIndex大于endIndex - 从以下版本开始:
- 1.4
-
concat
public String concat(String str)
将指定的字符串连接到该字符串的末尾。如果参数字符串的长度为
0,则返回此String对象。 否则,返回一个String对象,表示一个字符序列,该字符序列是由该String对象表示的字符序列与由参数字符串表示的字符序列的级联。例子:
"cares".concat("s") returns "caress" "to".concat("get").concat("her") returns "together"- 参数
-
str-String被连接到这个String。 - 结果
- 一个字符串,表示此对象的字符后跟字符串参数的字符的并置。
-
replace
public String replace(char oldChar, char newChar)
返回从替换所有出现的导致一个字符串oldChar在此字符串newChar。如果在String
oldChar表示的字符序列中没有发生String,则返回对该String对象的引用。 否则,String被返回对象,它表示一个字符序列与由本表示的字符序列String除了的每次出现对象,oldChar通过的发生替换newChar。例子:
"mesquite in your cellar".replace('e', 'o') returns "mosquito in your collar" "the war of baronets".replace('r', 'y') returns "the way of bayonets" "sparring with a purple porpoise".replace('p', 't') returns "starring with a turtle tortoise" "JonL".replace('q', 'x') returns "JonL" (no change)- 参数
-
oldChar- 老字。 -
newChar- 新角色。 - 结果
-
通过替换的每次出现从这个串衍生出的字符串
oldChar与newChar。
-
matches
public boolean matches(String regex)
告诉这个字符串是否匹配给定的regular expression 。这种形式为str
.matches(regex)方法的)产生与表达式完全相同的结果Pattern.matches(regex, str)- 参数
-
regex- 要匹配此字符串的正则表达式 - 结果
-
true如果,并且只有这个字符串与给定的正则表达式匹配 - 异常
-
PatternSyntaxException- 如果正则表达式的语法无效 - 从以下版本开始:
- 1.4
- 另请参见:
-
Pattern
-
contains
public boolean contains(CharSequence s)
当且仅当此字符串包含指定的char值序列时才返回true。- 参数
-
s- 搜索的顺序 - 结果
-
如果此字符串包含
s,则为true,否则为false - 从以下版本开始:
- 1.5
-
replaceFirst
public String replaceFirst(String regex, String replacement)
用给定的替换替换与给定的regular expression匹配的此字符串的第一个子字符串。这种形式为str
.replaceFirst(regex,repl)方法的)产生与表达式完全相同的结果Pattern.compile(regex).matcher(str).replaceFirst(repl)请注意,替换字符串中的反斜杠(
\)和美元符号($)可能会导致结果与被视为文字替换字符串时的结果不同; 见Matcher.replaceFirst(java.lang.String)。 如果需要,使用Matcher.quoteReplacement(java.lang.String)来抑制这些字符的特殊含义。- 参数
-
regex- 要匹配此字符串的正则表达式 -
replacement- 要替换第一个匹配的字符串 - 结果
-
结果
String - 异常
-
PatternSyntaxException- 如果正则表达式的语法无效 - 从以下版本开始:
- 1.4
- 另请参见:
-
Pattern
-
replaceAll
public String replaceAll(String regex, String replacement)
用给定的替换替换与给定的regular expression匹配的此字符串的每个子字符串。这种形式为str
.replaceAll(regex,repl)方法的)产生与表达式完全相同的结果Pattern.compile(regex).matcher(str).replaceAll(repl)请注意,替换字符串中的反斜杠(
\)和美元符号($)可能会导致结果与被视为文字替换字符串时的结果不同; 见Matcher.replaceAll。 如果需要,使用Matcher.quoteReplacement(java.lang.String)来抑制这些字符的特殊含义。- 参数
-
regex- 要匹配此字符串的正则表达式 -
replacement- 要替换每个匹配的字符串 - 结果
-
所得
String - 异常
-
PatternSyntaxException- 如果正则表达式的语法无效 - 从以下版本开始:
- 1.4
- 另请参见:
-
Pattern
-
replace
public String replace(CharSequence target, CharSequence replacement)
将与字面目标序列匹配的字符串的每个子字符串替换为指定的字面替换序列。 替换从字符串开始到结束,例如,在字符串“aaa”中用“b”替换“aa”将导致“ba”而不是“ab”。- 参数
-
target- 要替换的char值序列 -
replacement- char值的替换顺序 - 结果
- 生成的字符串
- 从以下版本开始:
- 1.5
-
split
public String[] split(String regex, int limit)
将此字符串拆分为给定的regular expression的匹配。此方法返回的数组包含此字符串的每个子字符串,该字符串由与给定表达式匹配的另一个子字符串终止,或由字符串结尾终止。 数组中的子字符串按照它们在此字符串中的顺序排列。 如果表达式与输入的任何部分不匹配,则生成的数组只有一个元素,即这个字符串。
当在此字符串的开始处存在正宽度匹配时,在结果数组的开始处包含空的前导子字符串。 开始时的零宽度匹配不会产生这样的空的前导子串。
limit参数控制应用模式的次数,因此影响生成的数组的长度。 如果极限n大于0,则模式最多应用n -1次,数组的长度不大于n ,数组的最后一个条目将包含超出最后一个匹配分隔符的所有输入。 如果n是非正的,那么模式将被应用到尽可能多的次数,并且数组可以有任何长度。 如果n为0,则模式将被应用尽可能多次,数组可以有任何长度,并且尾随的空字符串将被丢弃。例如,字符串
"boo:and:foo"使用以下参数产生以下结果:Regex Limit Result : 2 { "boo", "and:foo" }: 5 { "boo", "and", "foo" }: -2 { "boo", "and", "foo" }o 5 { "b", "", ":and:f", "", "" }o -2 { "b", "", ":and:f", "", "" }o 0 { "b", "", ":and:f" }调用此方法的形式str。
split(正则表达式,n)产生与表达式相同的结果Pattern.compile(regex).split(str, n)- 参数
-
regex- 分隔正则表达式 -
limit- 结果阈值,如上所述 - 结果
- 通过将该字符串围绕给定的正则表达式的匹配来计算的字符串数组
- 异常
-
PatternSyntaxException- 如果正则表达式的语法无效 - 从以下版本开始:
- 1.4
- 另请参见:
-
Pattern
-
split
public String[] split(String regex)
将此字符串拆分为给定的regular expression的匹配。该方法的工作原理是通过使用给定表达式和限制参数为零调用双参数
split方法。 因此,尾随的空字符串不会包含在结果数组中。例如,字符串
"boo:and:foo"使用以下表达式得到以下结果:Regex Result : { "boo", "and", "foo" }o { "b", "", ":and:f" }- 参数
-
regex- 分隔正则表达式 - 结果
- 通过将该字符串围绕给定的正则表达式的匹配来计算的字符串数组
- 异常
-
PatternSyntaxException- 如果正则表达式的语法无效 - 从以下版本开始:
- 1.4
- 另请参见:
-
Pattern
-
join
public static String join(CharSequence delimiter, CharSequence... elements)
返回一个新的字符串,由CharSequence elements的副本组成,并附有指定的delimiter的delimiter。For example,
请注意,如果元素为空,则添加String message = String.join("-", "Java", "is", "cool"); // message returned is: "Java-is-cool""null"。- 参数
-
delimiter- 分隔每个元素的分隔符 -
elements- 要加入的元素。 - 结果
-
一个新的
String,其由所述的elements由分离delimiter - 异常
-
NullPointerException- 如果delimiter或elements是null - 从以下版本开始:
- 1.8
- 另请参见:
-
StringJoiner
-
join
public static String join(CharSequence delimiter, Iterable<? extends CharSequence> elements)
返回一个新String的副本组成CharSequence elements与指定的副本一起加入delimiter。For example,
请注意,如果单个元素为List<String> strings = new LinkedList<>(); strings.add("Java");strings.add("is"); strings.add("cool"); String message = String.join(" ", strings); //message returned is: "Java is cool" Set<String> strings = new LinkedHashSet<>(); strings.add("Java"); strings.add("is"); strings.add("very"); strings.add("cool"); String message = String.join("-", strings); //message returned is: "Java-is-very-cool"null,则添加"null"。- 参数
-
delimiter- 用于分离elements中的每一个的elements序列String -
elements- 一个Iterable,将其elements连接在一起。 - 结果
-
一个新的
String由elements参数组成 - 异常
-
NullPointerException- 如果delimiter或elements是null - 从以下版本开始:
- 1.8
- 另请参见:
-
join(CharSequence,CharSequence...),StringJoiner
-
toLowerCase
public String toLowerCase(Locale locale)
将所有在此字符String,以降低使用给定的规则情况下Locale。 案例映射基于Character类指定的Unicode标准版本。 由于情况的映射并不总是1:1字符映射,将所得String可以是不同的长度比原来的String。小写映射示例如下表所示:
Language Code of Locale Upper Case Lower Case Description tr (Turkish) \u0130 \u0069 capital letter I with dot above -> small letter i tr (Turkish) \u0049 \u0131 capital letter I -> small letter dotless i (all) French Fries french fries lowercased all chars in String (all)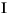
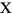
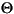
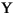
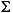
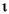
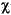
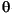
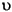
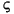 lowercased all chars in String
lowercased all chars in String
- 参数
-
locale- 使用此区域设置的案例转换规则 - 结果
-
String,转换成小写。 - 从以下版本开始:
- 1.1
- 另请参见:
-
toLowerCase(),toUpperCase(),toUpperCase(Locale)
-
toLowerCase
public String toLowerCase()
将所有在此字符String使用默认语言环境的规则,以小写。 这相当于打电话toLowerCase(Locale.getDefault())。注意:此方法是区域设置敏感的,如果用于单独解释区域设置的字符串,可能会产生意外的结果。 示例是编程语言标识符,协议密钥和HTML标签。 例如,
"TITLE".toLowerCase()在土耳其语言环境返回"t\u0131tle",其中“\ u0131”是拉丁小写字母无点我的性格。 要获取区域设置不敏感字符串的正确结果,请使用toLowerCase(Locale.ROOT)。- 结果
-
String,转换成小写。 - 另请参见:
-
toLowerCase(Locale)
-
toUpperCase
public String toUpperCase(Locale locale)
将所有在此字符String使用给定的规则,大写Locale。 案例映射基于Character类指定的Unicode标准版本。 由于案例映射并不总是1:1的字符映射,所以String可能与原始的String。区域设置敏感和1:M情况映射的示例如下表所示。
Language Code of Locale Lower Case Upper Case Description tr (Turkish) \u0069 \u0130 small letter i -> capital letter I with dot above tr (Turkish) \u0131 \u0049 small letter dotless i -> capital letter I (all) \u00df \u0053 \u0053 small letter sharp s -> two letters: SS (all) Fahrvergnügen FAHRVERGNÜGEN- 参数
-
locale- 使用此区域设置的案例转换规则 - 结果
-
String,转换成大写。 - 从以下版本开始:
- 1.1
- 另请参见:
-
toUpperCase(),toLowerCase(),toLowerCase(Locale)
-
toUpperCase
public String toUpperCase()
使用默认语言环境的规则将此String中的所有字符转换为大写。 此方法相当于toUpperCase(Locale.getDefault())。注意:此方法是区域设置敏感的,如果用于单独解释区域设置的字符串,可能会产生意外的结果。 示例是编程语言标识符,协议密钥和HTML标签。 例如,
"title".toUpperCase()在土耳其语言环境返回"T\u0130TLE",其中“\ u0130”是拉丁文大写字母我带点上述特征。 要获得不区分大小写字符串的正确结果,请使用toUpperCase(Locale.ROOT)。- 结果
-
的
String,转换为大写。 - 另请参见:
-
toUpperCase(Locale)
-
trim
public String trim()
返回一个字符串,其值为此字符串,并删除任何前导和尾随空格。如果此
String对象表示一个空字符序列,或由该代表字符序列的第一个和最后一个字符String对象都具有代码大于'\u0020'(空格字符),则此参考String被返回对象。否则,如果字符串中没有字符大于
'\u0020'的字符,则返回一个表示空字符串的String对象。否则,令k为代码大于'\u0020'的字符串中第一个字符的
'\u0020',并且m为代码大于'\u0020'的字符串中最后一个字符的'\u0020'。 将返回一个String对象,表示该字符串的子字符串,以索引k处的字符开头,以索引m为止的字符结束,结果为this.substring(k, m + 1)。此方法可用于从字符串的开始和结尾修剪空格(如上定义)。
- 结果
- 一个字符串,其值是此字符串,除去任何前导和尾随空格,或者如果该字符串没有前导或尾随的空格,则为该字符串。
-
toString
public String toString()
此对象(已经是字符串!)本身已被返回。- Specified by:
-
toString在界面CharSequence - 重写:
-
toString在类别Object - 结果
- 字符串本身。
-
toCharArray
public char[] toCharArray()
将此字符串转换为新的字符数组。- 结果
- 一个新分配的字符数组,其长度是该字符串的长度,其内容被初始化为包含由该字符串表示的字符序列。
-
format
public static String format(String format, Object... args)
使用指定的格式字符串和参数返回格式化的字符串。总是使用的区域是
Locale.getDefault()返回的地方 。- 参数
-
format- A format string -
args- 格式字符串中格式说明符引用的参数。 如果比格式说明符更多的参数,额外的参数将被忽略。 参数的数量是可变的,可能为零。 参数的最大数量受限于The Java™ Virtual Machine Specification定义的Java数组的最大维数 。 一个null参数的行为取决于conversion 。 - 结果
- 格式化的字符串
- 异常
-
IllegalFormatException- 如果格式字符串包含非法语法,则与给定参数不兼容的格式说明符,给定格式字符串的参数不足或其他非法条件。 有关所有可能的格式化错误的规范 ,请参阅格式化程序类规范的Details部分。 - 从以下版本开始:
- 1.5
- 另请参见:
-
Formatter
-
format
public static String format(Locale l, String format, Object... args)
使用指定的区域设置,格式字符串和参数返回格式化的字符串。- 参数
-
l- 格式化期间应用的locale。 如果l是null,则不应用本地化。 -
format- A format string -
args- 格式字符串中格式说明符引用的参数。 如果比格式说明符更多的参数,额外的参数将被忽略。 参数的数量是可变的,可能为零。 参数的最大数量受到The Java™ Virtual Machine Specification定义的Java数组的最大维度的限制 。 一个null参数的行为取决于conversion 。 - 结果
- 格式化的字符串
- 异常
-
IllegalFormatException- 如果格式字符串包含非法语法,则与给定参数不兼容的格式说明符,给定格式字符串的参数不足或其他非法条件。 有关所有可能的格式化错误的规范 ,请参阅格式化程序类规范的Details部分 - 从以下版本开始:
- 1.5
- 另请参见:
-
Formatter
-
valueOf
public static String valueOf(Object obj)
返回Object参数的字符串Object形式。- 参数
-
obj- 一个Object。 - 结果
-
如果参数是
null,那么一个字符串等于"null"; 否则返回值obj.toString()。 - 另请参见:
-
Object.toString()
-
valueOf
public static String valueOf(char[] data)
返回char数组参数的字符串char形式。 字符数组的内容被复制; 字符数组的后续修改不会影响返回的字符串。- 参数
-
data- 字符数组。 - 结果
-
一个
String,其中包含字符数组的字符。
-
valueOf
public static String valueOf(char[] data, int offset, int count)
返回char数组参数的特定子阵列的字符串char形式。offset参数是子阵列的第一个字符的索引。count参数指定子数组的长度。 副本的内容被复制; 字符数组的后续修改不会影响返回的字符串。- 参数
-
data- 字符数组。 -
offset- 子阵列的初始偏移量。 -
count- 子阵列的长度。 - 结果
-
一个
String,其中包含字符数组的指定子阵列的字符。 - 异常
-
IndexOutOfBoundsException- 如果offset为负数,或count为负数,或offset+count大于data.length。
-
copyValueOf
public static String copyValueOf(char[] data, int offset, int count)
- 参数
-
data- 字符数组。 -
offset- 子阵列的初始偏移量。 -
count- 子阵列的长度。 - 结果
-
一个
String,其中包含字符数组的指定子阵列的字符。 - 异常
-
IndexOutOfBoundsException- 如果offset为负数,或count为负数,或offset+count大于data.length。
-
copyValueOf
public static String copyValueOf(char[] data)
相当于valueOf(char[])。- 参数
-
data- 字符数组。 - 结果
-
一个
String包含字符阵列的字符。
-
valueOf
public static String valueOf(boolean b)
返回boolean参数的字符串boolean形式。- 参数
-
b- aboolean。 - 结果
-
如果参数为
true,则返回等于"true"的字符串; 否则,等于一个字符串"false"返回。
-
valueOf
public static String valueOf(char c)
返回char参数的字符串char形式。- 参数
-
c- achar。 - 结果
-
长度为
1的字符串以其单个字符包含参数c。
-
valueOf
public static String valueOf(int i)
返回int参数的字符串int形式。该表示恰好是一个参数的
Integer.toString方法返回的表示。- 参数
-
i-int。 - 结果
-
一个字符串表示的
int参数。 - 另请参见:
-
Integer.toString(int, int)
-
valueOf
public static String valueOf(long l)
返回long参数的字符串long形式。该表示恰好是一个参数的
Long.toString方法返回的表示。- 参数
-
l- along。 - 结果
-
一个字符串表示的
long参数。 - 另请参见:
-
Long.toString(long)
-
valueOf
public static String valueOf(float f)
返回float参数的字符串float形式。该表示恰好是一个参数的
Float.toString方法返回的表示。- 参数
-
f- afloat。 - 结果
-
float参数的字符串表示。 - 另请参见:
-
Float.toString(float)
-
valueOf
public static String valueOf(double d)
返回double参数的字符串double形式。该表示恰好是一个参数的
Double.toString方法返回的表示。- 参数
-
d- adouble。 - 结果
-
double参数的字符串double形式。 - 另请参见:
-
Double.toString(double)
-
intern
public String intern()
返回字符串对象的规范表示。最初为空的字符串池由
String类String。当调用intern方法时,如果池已经包含与
equals(Object)方法确定的相当于此String对象的字符串,则返回来自池的字符串。 否则,此String对象将添加到池中,并返回对此String对象的引用。由此可见,对于任何两个字符串
s和t,s.intern() == t.intern()是true当且仅当s.equals(t)是true。所有文字字符串和字符串值常量表达式都被实体化。 字符串文字在The Java™ Language Specification的 3.10.5节中定义。
- 结果
- 一个字符串与该字符串具有相同的内容,但保证来自一个唯一的字符串池。
-
-